EXALT
Welcome to the web page of EXALT, the first shared task on explainability of cross-lingual emotion detection. With recent developments of large, opaque, black box systems behind APIs, it is becoming harder and harder to understand the rationales behind decisions made by these models for subjective tasks. To look further into one such direction, we aim to better understand the decision making of emotion detection systems and assess if they are capable of understanding the triggers of emotion in social media data.
The task will be organized within the 14th Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis (WASSA). WASSA will be co-located with the Annual Meeting of the Association of Computational Linguistics (ACL) 2024 in Bangkok, Thailand.
Organizers
1. Language & Translation Technology Team, Ghent University
Introduction and Motivation
Emotion detection is a well-studied task in the field of NLP and has already been addressed in previous runs of SemEval1,2. In this shared task, we want to go one step further and offer a manually annotated multilingual benchmark data set, where not only emotions are labeled, but also the words triggering these emotions. To this end, we want to investigate to what extent emotion information is transferable across languages, by offering training data in English, and evaluation data for 5 different target languages, namely Dutch, Russian, Spanish, English, and French. In addition, predicting trigger words should be a first step to endorsing emotion detection systems with a means to explain why a specific emotion has been predicted. With an ever-rising flurry of black-box models, we want to encourage research that moves towards the interpretability and explainability of the systems.
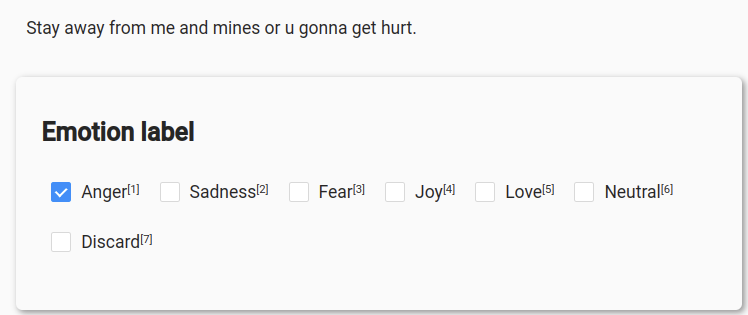
As there is no real consensus on a standard emotion labeling framework, we opted to apply the label set of Debruyne et al.3, which is justified both theoretically and practically. Frequency and cluster analysis of tweet annotations resulted in a label set containing the 5 emotions: Love, Joy, Anger, Fear and Sadness. This label set certainly shows a resemblance to Ekman’s basic emotions, but due to the applied data-driven approach, the label set is more grounded in the task of emotion detection in text. As we did not crawl our data based on emojis (as was the case for Debruyne et al.), we also added a Neutral emotion label to the emotion label set.
1. Saif Mohammad, Felipe Bravo-Marquez, Mohammad Salameh, and Svetlana Kiritchenko. 2018b. SemEval-2018 task 1: Affect in tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation, pages 1–17, New Orleans, Louisiana. Association for Computational Linguistics.
2. Ankush Chatterjee, Kedhar Nath Narahari, Meghana Joshi, and Puneet Agrawal. 2019. SemEval-2019 task 3: EmoContext contextual emotion detection in text. In Proceedings of the 13th International Workshop on Semantic Evaluation, pages 39–48, Minneapolis, Minnesota, USA. Association for Computational Linguistics.
3. Luna De Bruyne, Orphée De Clercq, and Veronique Hoste. 2019. Towards an empirically grounded framework for emotion analysis. In Proceedings of HUSO 2019, the fifth international conference on human and social analytics, pages 11–16. IARIA, International Academy, Research, and Industry Association.
Task Description
We present a cross-lingual emotion detection task, that consists of the following two sub-tasks:
1. Cross-lingual emotion detection task:
Predict for each tweet the correct emotion label from 6 possible classes: Love,
Joy, Anger, Fear, Sadness, Neutral in five target languages. More concretely, we present the participants with an English data set of 6000 tweets, which can be used for training and validation. For the evaluation phase, we then present smaller test sets of 500 tweets for each of the test languages.
Note: The participants are free to use additional training resources, though they should be restricted to English only to evaluate the efficacy of the cross-lingual setup.
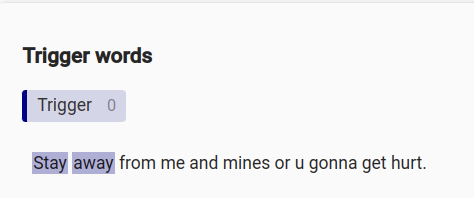
2. Predict the text span triggering the predicted emotion label:
For the second task, we propose trigger word detection, a token-classification task that is focused on explaining which words are used to express the emotion. Detailed information on how these trigger words have been labeled can be found in the annotation guidelines.
Data
The dataset will be available on the Codalab page from the 15th of February, 2024.
The test set will be available in the same repository from May 13th, 2024. The training data will be available in English, and the test data will be available in the following languages: Dutch, Russian, Spanish, English, and French.
Evaluation
Each participating team will initially have access to the training data only. The unlabelled test data will be released at a later date(see the timeframe here) After the evaluation phase is complete, the labels for the test data will be released as well.
Task 1 - Emotion Detection
We report the following three metrics for the emotion detection task:
- Macro-averaged Precision
- Macro-averaged Recall
- Macro-averaged F1-score
Task 2 - Binary Trigger Word Detection
The task for binary trigger word detection will be evaluated as a token classification task. We report the following metrics for binary trigger word detection (calculated on token-level and averaged across instances):
- Token Precision
- Token Recall
- Token F1-score
- Mean Average Precision
Task 3 - Numerical Trigger Word Detection
UPDATED: Since most feature importance attributions approaches provide numerical importances for each (sub-) token, evaluation for binary trigger word detection usually requires imposing a threshold to convert the score to 0 or 1. As this threshold loses the nuance of the exact importance value, we also include evaluation of the direct numerical outputs. For this evaluation of numerical outputs we calculate a new metric, called Accumulated Precise Attribution. After normalization (ignoring negative values and makiung sure the attributions for each sentence add up to 1), this metric adds up the attributions for each trigger word (meaning the tokens with a 1-label). With this score, we can tell how much of the total importance was attributed to human-indicated trigger words and how much of it was attributed to irrelevant tokens.
Baselines
For both sub-tasks, we will compute a first baseline. The code and scores will also be made available on the Github page.
Update: The baseline scores and code are now available! You can find the baseline scores on the dev set under the submission name "EXALT-Baseline" on the competition page. The code for implementing the baseline for both sub-tasks is available on the Github page in the "starters_kit" folder.
How To Participate
Register your team by using the registration web form here.
Information about the submission of results and their format will be available on the Codalab page.
We invite the potential participants to subscribe to our Google Group in order to be kept up to date with the latest news related to the task. Please share comments and questions with the mailing list. The organizers can then assist you with issues and questions.
Participants will be required to provide an abstract and a technical report including a brief description of their approach, an illustration of their experiments, in particular techniques and resources used, and an analysis of their results for the publication in the Proceedings of the task.
Important Dates
15th February 2024: Training data available on Codalab
13th May 2024: Evaluation phase begins. Test data available.
15th May 2024: Final submissions. End of evaluation phase.
26th May 2024: Deadline for submission of system description papers
22nd June 2024: Notification of acceptance
1st July 2024: Camera-ready papers due
15th-16th August 2024: Final workshop in Bangkok, Thailand.(online & in-person)
Official Rankings
Contact Us
Write to us here!
Or contact the organizers: Aaron Maladry and Pranaydeep Singh.
Website template credits: Mirko Lai